
Introduction
Sentiment analysis is a fundamental task in natural language processing (NLP) that focuses on identifying the emotional tone behind textual data. From product reviews and social media posts to movie critiques, understanding sentiment helps businesses and researchers extract meaningful insights from large volumes of text. One of the most commonly used benchmark datasets for this task is the IMDB movie reviews dataset, which contains labeled positive and negative reviews.
Recurrent Neural Networks (RNNs) have traditionally been a popular choice for sentiment analysis because they are designed to handle sequential data such as text. However, standard RNNs often struggle with long-term dependencies, which led to the development of improved architectures like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks.
In this blog, we present a comparative study of Vanilla RNN, LSTM, and GRU for sentiment analysis on the IMDB dataset. We evaluate their performance, training behavior, and practical trade-offs to understand which architecture is best suited for this task.
Why Sentiment Analysis with RNNs?
Text data is inherently sequential. The meaning of a word often depends on the words that come before it, making sequence modeling essential for NLP tasks. RNNs are specifically designed to process sequences by maintaining a hidden state that captures information from previous time steps.
For sentiment analysis, this sequential modeling capability allows RNN-based models to understand context, negations, and dependencies across words in a sentence or paragraph. For example, phrases like “not good” or “although the movie started slow, it ended brilliantly” require contextual understanding that simple bag-of-words models often fail to capture.
Despite newer architectures like Transformers gaining popularity, RNN-based models remain important for understanding the evolution of sequence modeling and for use cases where computational resources are limited.
IMDB Dataset Overview
The IMDB dataset is a widely used benchmark for binary sentiment classification. It consists of movie reviews labeled as either positive or negative, making it ideal for evaluating text classification models.
Dataset Characteristics
-
Task: Binary sentiment classification (positive / negative)
-
Total reviews: 50,000
-
Training set: 25,000 reviews
-
Test set: 25,000 reviews
-
Balanced classes: Equal number of positive and negative samples
Preprocessing Steps
Common preprocessing steps applied to the IMDB dataset include:
-
Text tokenization
-
Converting words into integer indices
-
Limiting vocabulary size
-
Padding or truncating sequences to a fixed length
These steps ensure that the text data can be efficiently processed by neural network models.
Recurrent Neural Network Architectures
This section provides a high-level overview of the three RNN architectures compared in this study.
Vanilla RNN
The Vanilla RNN is the simplest form of recurrent neural network. It processes sequences by updating a hidden state at each time step using the current input and the previous hidden state.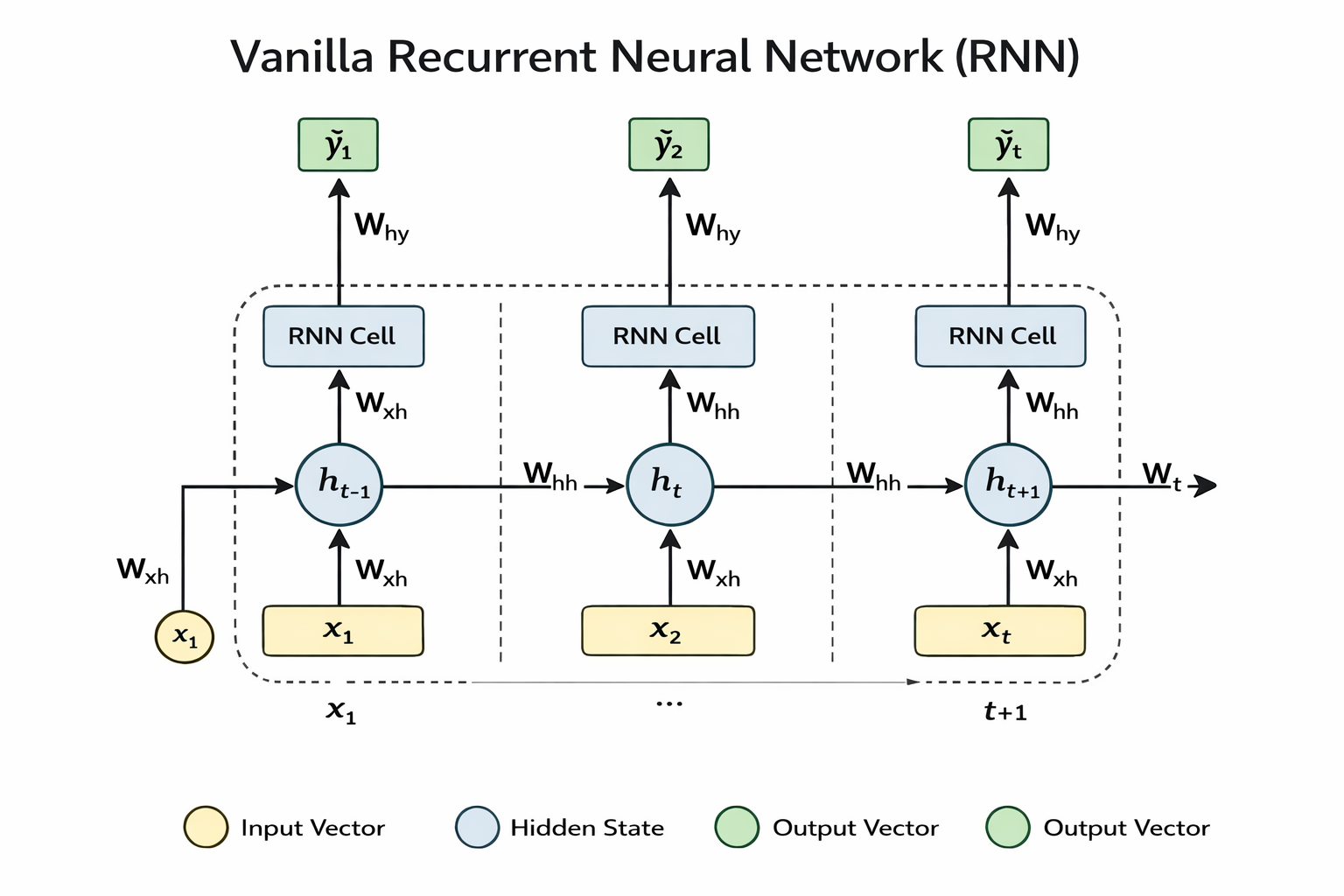
Advantages:
Simple and easy to implement
Fewer parameters
Useful for short sequences
Limitations:
Suffers from the vanishing gradient problem
Struggles with long-term dependencies
Performance degrades on longer text sequences
Because IMDB reviews can be lengthy, vanilla RNNs often fail to retain important contextual information from earlier parts of the review.
Long Short-Term Memory (LSTM)
LSTM networks were introduced to overcome the limitations of vanilla RNNs. They use a gated architecture that controls the flow of information through the network.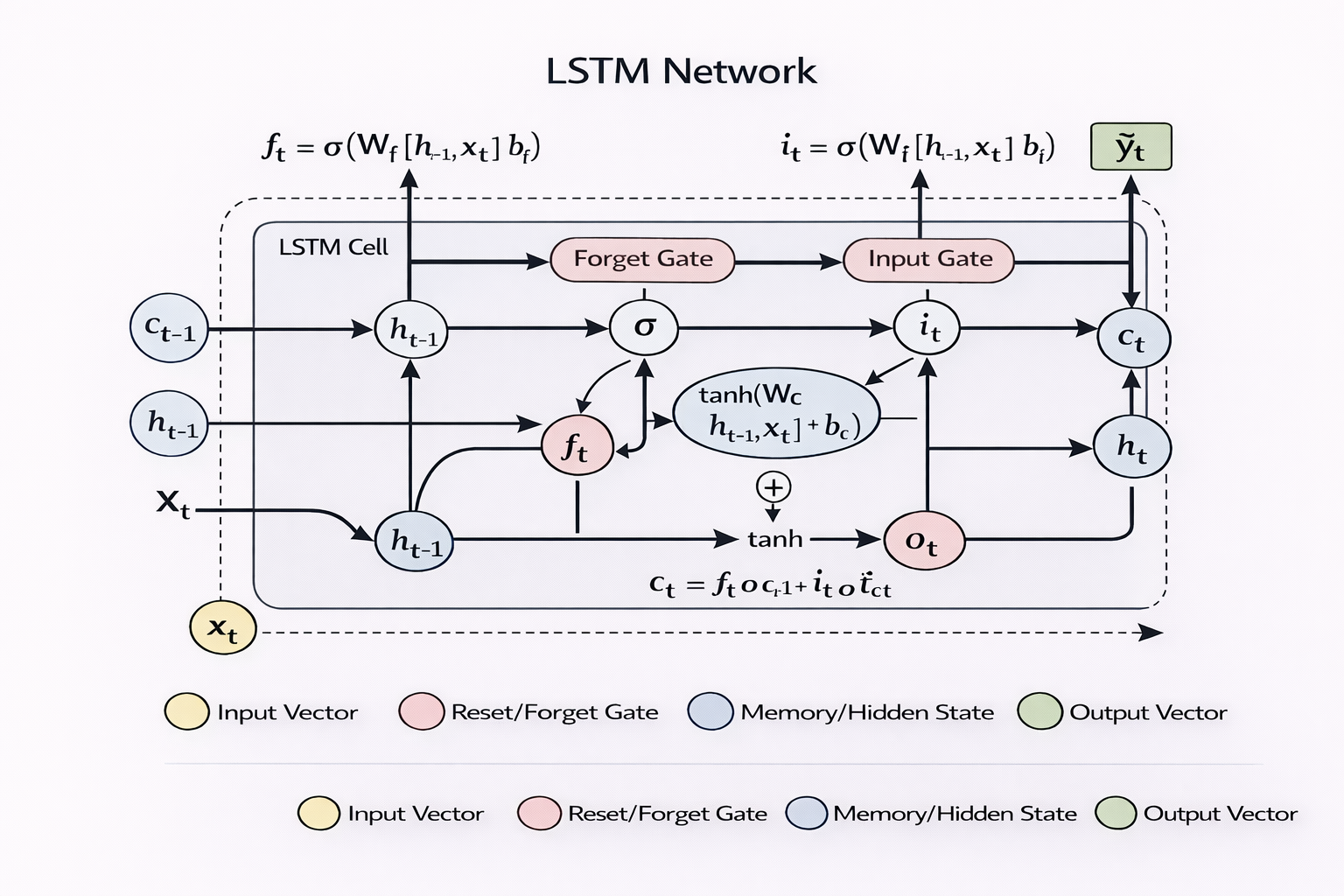
Key components of LSTM include:
Forget gate
Input gate
Output gate
Cell state
These mechanisms allow LSTMs to selectively remember or forget information over long sequences.
Advantages:
Excellent at capturing long-term dependencies
Stable training behavior
Strong performance on text-based tasks
Limitations:
Computationally expensive
Larger number of parameters
Slower training compared to simpler models
Want to learn more about RNN and LSTM architecture ? Read our detailed guide explaining how Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) models work.
Gated Recurrent Unit (GRU)
GRU is a simplified variant of the LSTM architecture. It combines the forget and input gates into a single update gate and eliminates the separate cell state. Advantages:
Fewer parameters than LSTM
Faster training
Competitive performance on many NLP tasks
Limitations:
Slightly less expressive than LSTM in some cases
Performance differences depend on the dataset and task
GRUs often provide a good balance between efficiency and performance, especially when computational resources are constrained